
Koldo Basterretxea, Associate Professor at Universidad del País Vasco/Euskal Herriko Unibertsitatea.
La imagen hiperespectral (HyperSpectral Imaging o HSI), que ofrece información precisa sobre el espectro de reflectancia de los materiales, ya se está utilizando con éxito en varios ámbitos de aplicación como la observación terrestre, las geociencias, la agricultura de precisión, la exploración espacial o la industria alimentaria [1]. En los últimos años, los recientes avances en las tecnologías de detección HSI han permitido la comercialización de cámaras de tipo “snapshot”, capaces de capturar información espectral en decenas o incluso cientos de bandas a velocidades de vídeo [2]. Estos desarrollos han despertado un gran interés en explorar el potencial de la HSI en ámbitos de aplicación emergentes que requieren sistemas de imagen espectral asequibles, compactos y portátiles con un consumo de energía moderado a bajo. El Grupo de Diseño en Electrónica Digital (GDED) de la Universidad del País Vasco (EHU) inició hace algunos años la exploración del uso de los sensores HSI en el desarrollo de futuros sistemas de visión para conducción autónoma (Autonomous Driving o AD). El objetivo de esta línea de investigación es analizar el potencial de la HSI para superar las limitaciones de robustez presentes en los actuales sistemas de visión inteligente, así como investigar las posibilidades de ampliar las capacidades se estos sistemas con objeto de proporcionar una mayor comprensión del entorno (scene understanding) [3].
La integración de cámaras HSI snapshot en AD requiere un análisis cuidadoso de las tecnologías disponibles, así como la adecuación tanto de los algoritmos como de las arquitecturas de procesamiento de los sistemas de visión a los requisitos particulares de este campo de aplicación. Los desafíos en este campo de aplicación surgen de la combinación de varios factores que condicionan la calidad y precisión de la información recopilada por estos sensores: las limitaciones propias de las distintas tecnologías de cámaras snapshot, la ausencia de control sobre la iluminación de los objetos, la presencia de elementos en rápido movimiento, los tiempos de exposición variables, etc. Así, la selección de una cámara HSI para experimentar con el desarrollo de sistemas avanzados de visión artificial aplicados a AD debe basarse en un conjunto de criterios bien establecidos. Idealmente:
- Debe ser capaz de operar a velocidades de vídeo (snapshot cameras) bajo diferentes condiciones de iluminación.
- Debe ser pequeña, compacta y mecánicamente robusta.
- Debe ofrecer una resolución espacial y espectral suficiente para lograr una buena separabilidad espectral entre las clases o materiales a identificar.
- Debe estar basada en una tecnología de sensor escalable que la haga competitiva para una futura implantación masiva.
En lo que respecta a la capacidad de operar a velocidades de vídeo, un factor adicional que a menudo se omite, pero que es de extraordinaria importancia, es el de los requisitos de procesamiento necesarios para recuperar la información espacial y espectral a partir de los datos en crudo proporcionados por el sensor. Los principales actores en el segmento de cámaras HSI snapshot de formato reducido y alta velocidad (> 10–20 fps) emplean, bien tecnología de deposición on-chip de filtros de interferometría de banda estrecha (por ejemplo, los sensores de Imec utilizados en cámaras Ximea y Photonfocus), o bien tecnología light field basada en matrices de microlentes para la proyección múltiple de imágenes espectralmente filtradas sobre el sensor (como en el caso de Cubert). En ambos casos, la luz incidente se proyecta sobre un sensor CMOS estándar, lo que actualmente proporciona una ventaja con respecto a la disponibilidad y escalabilidad de estas tecnologías. Tecnologías alternativas, como la Coded Aperture Snapshot Spectral Imaging (CASSI), combinadas con muestreo espectral disperso, requieren un procesamiento de datos complejo y de gran carga computacional, por lo que en la actualidad estas cámaras no pueden satisfacer los mencionados requisitos para su uso en aplicaciones de conducción autónoma. Existen algunas nuevas tecnologías emergentes, como es el caso de la desarrollada por la empresa finlandesa AGATE que, si bien es prometedora, aun no se ha podido evaluar.
El dataset HSI-Drive
La investigación en este campo requiere, en primer lugar, de uno o varios conjuntos de datos que, en el momento en el que el GDED inició esta investigación, aún no existían. El conjunto de datos HSI-Drive se obtuvo a partir de grabaciones realizadas en campo con una cámara Photonfocus MV1D2048x1088- HS02-96-G2 equipada con un sensor Imec de 25 bandas en el rango Red-NIR basado en tecnología de filtros en mosaico on-chip (Fig. 1).

Las principales razones para la elección de esta tecnología fueron su costo relativamente bajo, una alta velocidad combinada con unas resoluciones espacial y espectral aceptables, y la accesibilidad a un código de procesamiento de generación de cubos espectrales que no resultaba demasiado complejo y que facilitaba así su adaptación y reprogramación para su ejecución eficiente en una plataforma de procesamiento embebida. Además, la tecnología de filtros espectrales sobre chip presenta una escalabilidad muy superior a la de sus competidoras, por lo que se valoró especialmente el hecho de que estos sensores podrían fabricarse en masa a un costo similar al de los sensores CMOS tradicionales.
No obstante, también existen algunos inconvenientes de esta tecnología que deben considerarse, como la presencia de fugas espectrales (spectral leakage) y picos de respuesta de segundo orden, las limitaciones impuestas por los patrones de mosaico en el número de bandas, y la necesidad de un realineamiento espacial de los píxeles de acuerdo con dichos patrones de filtros en mosaico. En conjunto, nuestro enfoque en el desarrollo de HSI-Drive se basó fundamentalmente en los principios de simplicidad y viabilidad, con un enfoque ingenieril en el que la realizabilidad futura de los sistemas desarrollados ha sido un factor transversal a toda la investigación. Este dataset, que contiene 752 imágenes etiquetadas manualmente a nivel de pixel y que se ofrece de forma pública para toda la comunidad científica, ya está disponible en su versión 2.1.1 [4].
El pipeline de procesamiento de datos utilizado para la generación de los cubos hiperespectrales en HSI-Drive 2.1 se ha optimizado para simplificar, en la medida de lo posible, su ejecución, ya que este proceso puede generar el principal cuello de botella de la aplicación en términos de carga computacional. El proceso, de forma resumida, consta de las siguientes fases:
- Recorte y encuadre de las imágenes.
- Eliminación del sesgo (bias removal) y corrección de reflectancia (reflectance
correction). - Demosaicing parcial (con una pérdida de resolución espacial del 1/5).
- Filtrado espacial (opcional).
- Traslación al centro (alineamiento de bandas mediante interpolación bilineal).
La corrección de reflectancia es un proceso especialmente sensible, ya que tiene como objetivo cancelar el espectro de irradiancia del iluminante y aislar el espectro de reflectancia de aquel. En un entorno de laboratorio, esto puede realizarse utilizando una loseta blanca calibrada y corrigiendo los datos de la imagen a procesar con los datos de una imagen blanca de referencia adquirida bajo las mismas condiciones de iluminación y con la misma configuración de cámara. En condiciones dinámicas en campo, sin embargo, una corrección de reflectancia precisa no es posible. En el GDED hemos desarrollado un algoritmo de “pseudo-corrección” de reflectancia que permite mejorar la coherencia de los datos utilizando datos de la propia imagen para estimar los niveles de iluminación relativos de cada escena. Esta estimación se realiza de forma dinámica u “on-the-fly» identificando los píxeles con mayor albedo en cada imagen, que suelen corresponder a superficies blancas de alta reflectancia, normalmente de las marcas viales sobre el asfalto u otras pinturas reflectantes blancas, carrocerías de vehículos pintadas en blanco etc. Comparando la irradiancia de estos píxeles con las imágenes blancas calibradas de referencia, se calcula un factor de escala que permite realizar la corrección. La identificación de píxeles de referencia para el escalado no es trivial, ya que implica descartar píxeles procedentes de fuentes de luz artificial (emisores de luz), como señales luminosas, semáforos o las luces delanteras y traseras de los vehículos. El algoritmo implementado segrega automáticamente estos píxeles “sospechosos” basándose en sus firmas espectrales, por lo que no requiere intervención humana y, por tanto, esta función puede integrarse directamente en el pipeline de procesamiento de imágenes del procesador de segmentación (véase un ejemplo en la Fig.2). Esta nueva técnica sustituye a la normalización por pixel (PN) utilizada en versiones anteriores del pipeline de procesamiento de HSI-Drive.

Los modelos de IA para HSI-Drive
Los modelos de segmentación de HSI-Drive son del tipo CNN (redes neuronales de convolución) codificador-decodificador con estructura U-Net (Fig. 3).
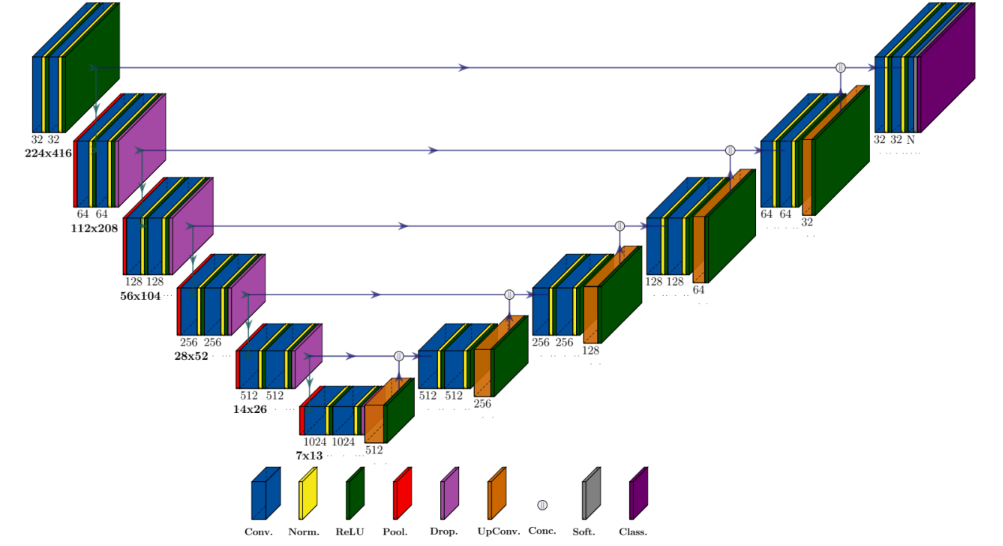
Estos modelos han sido mejorados en la última versión de HSI-Drive mediante la incorporación de módulos de atención espectral. Los mecanismos de atención se inspiran en el sistema visual humano, donde el cerebro prioriza selectivamente ciertas regiones del campo visual mientras suprime la información menos relevante. En las redes neuronales artificiales se implementa un principio similar al ponderar los mapas de características mediante una función de atención que permite que la red enfatice las características espaciales y espectrales más discriminativas (o una combinación de ambas), mejorando en última instancia su capacidad de representación. En particular, el denominado Efficient Channel Attention (ECA) funciona reajustando adaptativamente las características por canal sin recurrir a la reducción de dimensionalidad, y lo hace aplicando una interacción local entre canales mediante una convolución rápida 1D con un tamaño de núcleo determinado adaptativamente en función de la dimensión del canal. Este diseño evita la creación de capas neuronales adicionales y mantiene así tanto la precisión como la eficiencia y simplicidad de los modelos base, una característica necesaria para mantener la complejidad del modelo bajo control y permitir su ejecución en tiempo real.
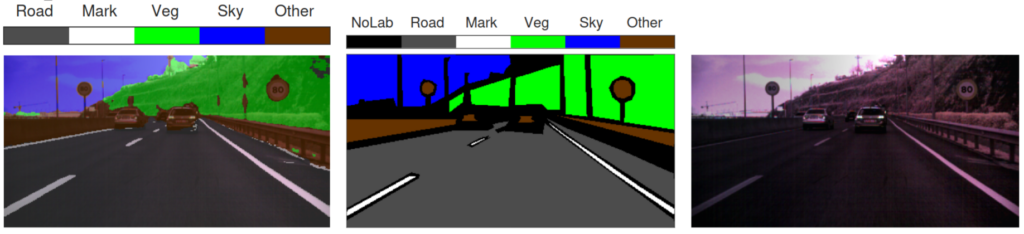
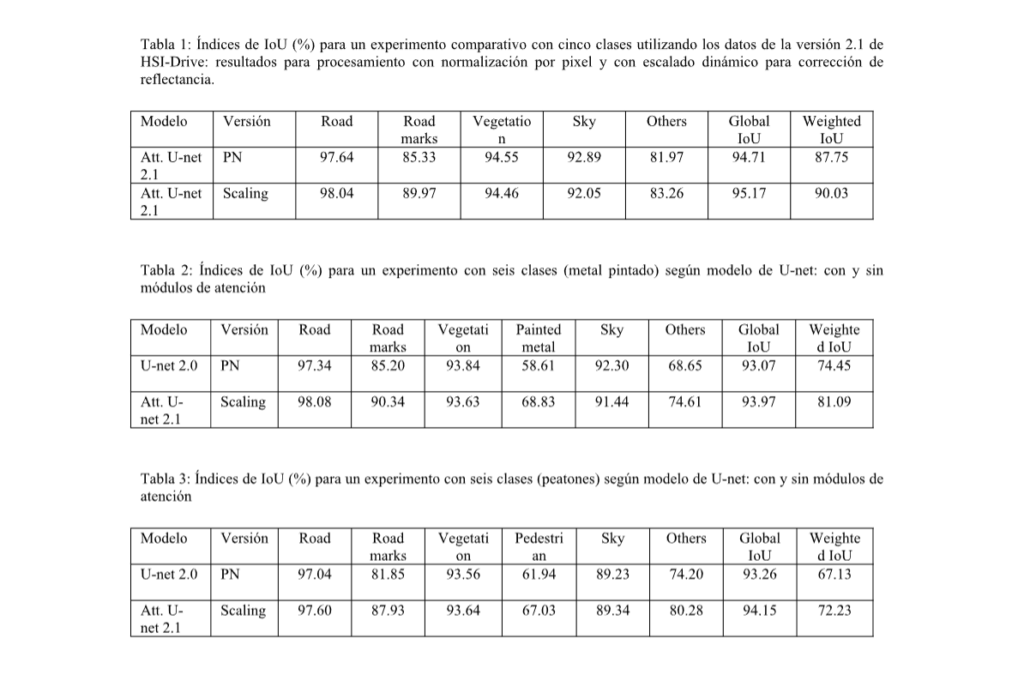
Los resultados obtenidos con los nuevos modelos de atención sobre los datos de HSI-Drive 2.1 avalan, tanto la incorporación de estos nuevos módulos, como el uso del algoritmo de pseudocorrección de reflectancia arriba descrito (escalado dinámico). Con la incorporación de los módulos de atención se han obtenido mejoras en los índices de clasificación más exigentes (weighted IoU) de entre el 2% y el 7%, según los experimentos y en función del número de clases a identificar. Por su parte, las segmentaciones obtenidas con el nuevo algoritmo de corrección con escalado dinámico generan mejoras de entorno a un 2% de forma consistente en todos los experimentos realizados, con especial beneficio en la clasificación de las clases más delicadas por presentar una mayor variabilidad intraclase y una menor separabilidad interclase. La Tablas 1 a 3 muestran resultados de test comparativos según la versión de la base de datos utilizada (v2.0 o v2.1), el método aplicado en tratamiento de los valores de reflectancia (PN o escalado dinámico), y el modelo entrenado (U-net o U-net con módulos de atención), tanto para un experimento con cinco clases (ver ejemplo de segmentación en Fig. 4) como en dos experimentos con seis clases (ver ejemplos en Fig. 5).

El entrenamiento y test de los modelos se ha realizado siguiendo una estrategia de validación cruzada estratificada con tres conjuntos de entrenamiento, uno de validación y uno de test. Los resultados de las tablas muestran los valores medios tras rondas de cinco entrenamientos. En el website de HSI-Drive (https://ipaccess.ehu.eus/HSI-Drive/) se pueden ver algunas secuencias de segmentación de video hyperespectral realizados con los modelos de mejor rendimiento.
El procesador HSI-Drive
Hemos desarrollado varios prototipos con tecnología PSoC/FPGA para el procesamiento en tiempo real del sistema de segmentación de HSI, tanto de la etapa de preprocesado de los datos del sensor (generación de los cubos hiperespectrales) como de los modelos CNN para inferencia. Uno de los últimos prototipos se ha implementado sobre un SOM AMD Kria KV26 de bajo consumo y bajo coste, apto para ser embarcado en plataformas móviles. Los valores de la caracterización del rendimiento del procesador sobre esta plataforma se muestran en la Tabla 4.
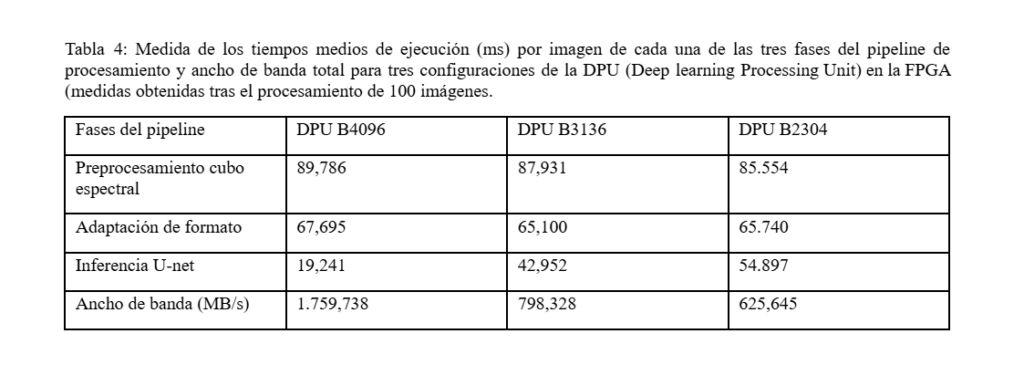
Para conseguir este rendimiento se han aplicado varias técnicas avanzadas de diseño, tanto en lo que se refiere a la compresión optimizada de los modelos (cuantización, poda etc.) como a la arquitectura SoC y la sincronización de procesos. En particular, para esta implementación se diseñó una ejecución en un pipeline de tres segmentos. Las dos primeras fases corresponden al preprocesamiento del cubo hiperespectral y a la adaptación del formato de codificación de los datos para la posterior fase de inferencia, que se ejecutan sobre sendos núcleos del Cortex-A53 embebido en el MPSoC de la K26 compartiendo los registros del SIMD. En esta versión, la inferencia del modelo CNN de segmentación, que es controlada por un tercer hilo de software, se ejecuta sobre un núcleo IP DPU B3136 (ver Fig. 6).
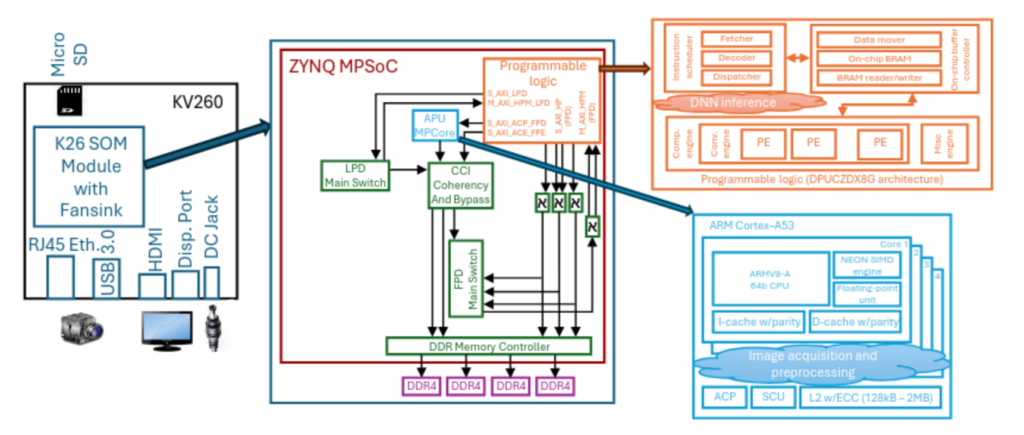
Esta no es la versión de más alto rendimiento posible en la configuración de la DPU, y fue seleccionada para optimizar el consumo y la ocupación de recursos en la FPGA. La sincronización se ha programado mediante variables de condición con buffers de salida independientes para prevenir carreras. Con esta configuración se consigue una latencia máxima de 87,138 ms, es decir, una velocidad de procesamiento de vídeo mínima de 11,5 fps, que es ligeramente superior a la frecuencia con la que se realizaron las grabaciones de las secuencias para HSI-Drive. Este rendimiento se consigue con tan solo 5.2 W de potencia media disipada en la K26, por lo que la energía consumida en el procesamiento de cada imagen, desde la adquisición de los datos en crudo hasta disponer de la salida segmentada en memoria externa DRAM, es de 0,453 J [5]. Se han podido obtener mayores velocidades utilizando dispositivos más potentes (más de 20 fps en una tarjeta ZCU104), pero esto resulta a costa de un mayor consumo de hasta 8.8W en el dispositivo [6].
Conclusión
En las líneas de investigación del GDED se combinan el conocimiento profundo de los algoritmos de procesamiento de la información, los fundamentos físicos de los sensores, las ciencias de la computación y el diseño de sistemas digitales complejos. La investigación en el desarrollo de sistemas embebidos de procesamiento e interpretación de imágenes hiperespectrales con aplicación a la conducción autónoma es un ejemplo de la actividad de este grupo de investigadores. Si bien ya se han conseguido verificar y caracterizar prototipos funcionales capaces de generar imágenes de segmentación semántica de escenas complejas a velocidades de video utilizando sensores HSI, aún hay camino que recorrer en el objetivo de demostrar que esta tecnología podría marcar la diferencia en los sistemas de interpretación del entorno y el guiado de vehículos autónomos en el futuro. Los próximos retos que abordaremos en esta línea serán múltiples: modificar los modelos y algoritmos para mejorar la precisión en el segmentado de los bordes de los objetos, optimizar la fase de preprocesamiento de datos para acelerar su computación y acercar el procesador al sensor para obtener un sistema más compacto, veloz y eficiente para su potencial despliegue en distintas plataformas móviles.
[1] Motoki Yako, “Hyperspectral imaging: history and prospects,” Optical Review, Sep 2025.
[2] Michael West, John Grossman, and Chris Galvan, “Commercial snapshot spectral imaging: the art of the possible,”, MTR180488 internal report. The MITRE Corporation, 2019.
[3] Imad Ali Shah, Jiarong Li, Martin Glavin, Edward Jones, Enda Ward, and Brian Deegan, “Hyperspectral imaging-based perception in autonomous driving scenarios: Benchmarking baseline semantic segmentation models”, in 2024 14th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Remote Sensing (WHISPERS), 2024, pp. 1–5.
[4] Koldo Basterretxea, Jon Gutiérrez-Zaballa, Javier Echanobe, and María Victoria Martínez, “HSI-Drive”, Zenodo Version v2.1.110.5281/zenodo.15687680
[5] Jon Gutiérrez-Zaballa, Koldo Basterretxea, and Javier Echanobe, “Optimization of DNN-based HSI Segmentation FPGA-based SoC for ADS: A Practical Approach”, ACM Journal of Sistems ARchitecture, 2025, doi 10.1145/3748722.
[6] Jon Gutiérrez-Zaballa, Koldo Basterretxea, Javier Echanobe, M. Victoria Martínez, Unai Martinez-Corral, Óscar Mata-Carballeira, Inés del Campo,”On-chip hyperspectral image segmentation with fully convolutional networks for scene understanding in autonomous driving”, ACM Journal of Systems Architecture, Vol. 139,2023,https://doi.org/10.1016/j.sysarc.2023.102878.