
Artificial Vision has emerged as an invaluable tool in a variety of fields, from manufacturing to medicine and autonomous driving. However, its effectiveness lies largely in the quality of the dataset used to train the models.
When implementing a computer vision system, the first decision is to choose which AI technology to use. We can summarise that the current options are Deep Learning, Reinforcement Learning and Deep Reinforcement Learning.
While Deep Learning excels at processing large datasets for perception tasks, Reinforcement Learning and Deep Reinforcement Learning are more suitable for sequential and dynamic decision-making problems. The choice between these techniques depends on the specific nature of the problem and the resources available for implementation. Most Computer Vision implementations, given the characteristics of the inference to be performed, are usually based on Deep Learning.
In a Deep Learning Computer Vision implementation, the generation of a robust and representative dataset is crucial to ensure that accurate and reliable inferences can be made in real-world situations.
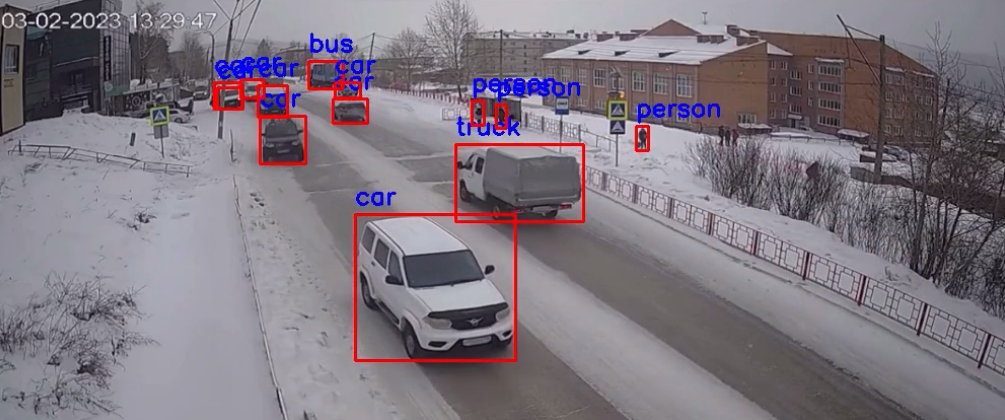
Artificial vision system detecting vehicle types and pedestrians in real time.
The complexity of generating a good dataset lies in several challenges. First, it is necessary to collect data covering a wide range of scenarios and conditions, which can require meticulous planning and image acquisition. In addition, accurate annotation of each image with relevant labels is essential for supervised learning, but this process can be laborious and prone to human error.
Once the dataset is generated, the next crucial step is to train the model in the cloud. This approach leverages the scalable computing power and storage resources available in the cloud to accelerate the training process and optimise model accuracy. However, even with a robust dataset and efficient cloud training, the true measure of a Computer Vision system’s success lies in its ability to make accurate and consistent inferences in real-world environments, where factors such as variable lighting, partial obstruction and the diversity of objects present can challenge even the most advanced systems. In this article, we will explore in detail the challenges and strategies for overcoming them at every stage of the process, from dataset generation to real-time inference.
EQUIP Electronics is a young electronics, cloud software and AI product development company based in Castellón. In the Artificial Intelligence business unit they have spent years developing their own Artificial Vision solutions that provide high performance in complex situations such as those described above (high speeds, poor lighting, diversity of objects, etc.).
The Artificial Vision solution developed by EQUIP Electronics consists of an integral solution formed by several applications using Deep Learning. The first one is a guided dataset generation software that facilitates the creation of a good dataset with a low number of images. Using innovative technologies such as Data Augmentation together with a powerful proprietary algorithm, results of up to 40-60% confidence increases have been obtained in cases of extreme complexity.
Once a good dataset has been generated from the metadata generated by the EQUIP Electronics software, automatic parameters are applied to train the model to get the most out of an optimised model for the inference application.
Finally, the inference application is able, from the optimised model already generated for the application, to detect the objects with a suitable framerate, apply different types of post-processing, generate reports and classify the assets.

A common application case for artificial vision is production lines.
We test the difference in performance by running 3 tests:
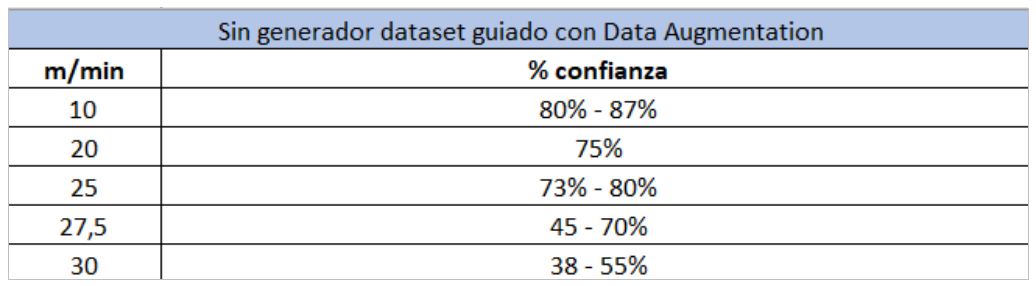
- CASE 1: Inference on a conveyor belt at different speeds (m/min) with a model generated without the Data Augmentation guided dataset generation system.
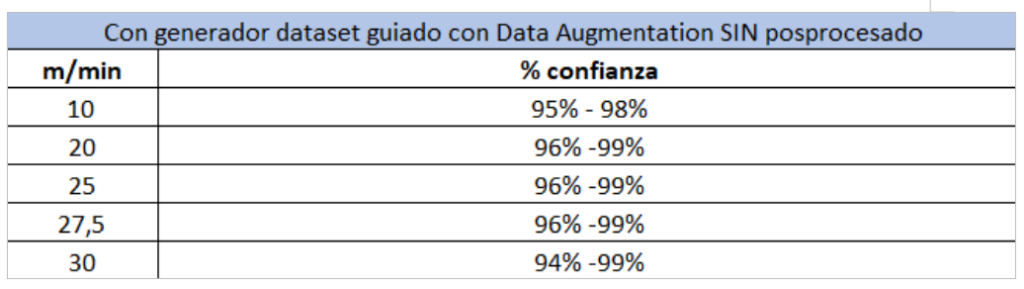
- CASE 2: The same test but using the guided dataset generation system with Data Augmentation.
- CASE 3: The same as in the previous experiment but activating all additional post-processing (contour, colour check, presence of components inside the objects to be detected, etc.).
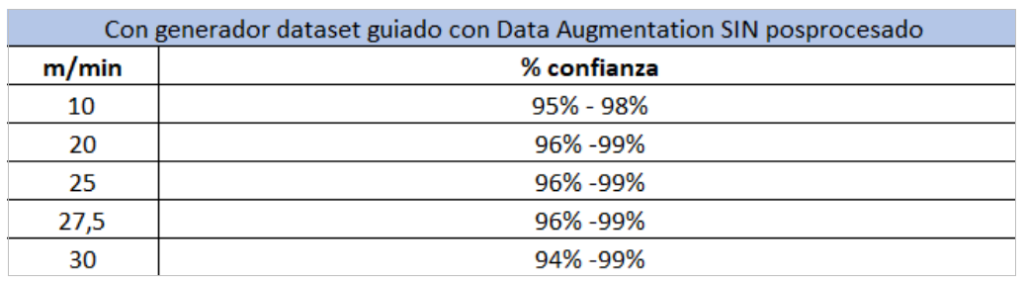
As we can see, the optimised dataset offers much better performance at higher speeds and with much smaller performance variations. Furthermore, the inference application does not reduce performance substantially when applying post-processing concurrently.
In short, a qualitative leap in the implementation of Artificial Vision systems applicable to industrial sectors (for quality control or occupational safety purposes), smart cities, among others, and resulting in greater productivity and quality of life for all.